
Cognitive Data Capture
Extraia valor dos documentos digitalizados de forma automatizada
Uma solução de Captura Cognitiva de Documentos permite combinar Inteligência Artificial com ferramentas low-code para eliminar o processamento manual de documentos, tornando rápida, precisa e fácil a sua classificação e a extração de informações, seja em formato estruturado ou não.
Operações ou processos de negócio que precisam em algum grau tratar e entender documentos, podem melhorar muito sua eficiência contando com uma solução que possa compreender esses documentos num nível contextual e detalhado, e disponibilizá-los à organização de forma digital.
Compreensão de documentos
Muitas áreas em uma organização precisam tratar documentos em papel (ou mesmo digitalizados – fotos, scanning…) em suas operações. Isso demanda um grau de esforço humano alto quando pensamos em todo o tratamento que precisa ser dado em cada um desses documentos para que sejam disponibilizados digitalmente dentro da organização, e possamos extrair algum valor do ponto de vista digital. Grosso modo, é preciso digitalizá-los, associá-los a algum tipo de categorização de negócios, extrair algumas informações para que sirvam como chave, método de pesquisa, contexto, além de toda a governança que precisa ser aplicada nesses assets.
Uma solução de Captura Cognitiva permite que uma série de etapas deste árduo processo possa ser realizada de uma forma muito mais eficiente, a partir do emprego de técnicas avançadas de Inteligência Artificial. Visando a compreensão dos documentos que precisam ser digitalizados, uma solução que permita a modelagem low-code de documentos e o seu treinamento rápido baseado em Deep Learning, reduz significativamente o número de amostras de documentos, anotações, e consequentemente o tempo necessário para treinar a tecnologia e colocá-la em funcionamento. Isso permite uma implantação ágil e uma rápida obtenção de valor pelas áreas de negócio.
Ao final, a tecnologia se encarrega de extrair valor dos documentos digitalizados, e, associada a um ECM, armazena tanto o asset (documento) quanto toda a sua compreensão neste repositório corporativo. A partir disso, o documento evolui para um status acionável por diversos processos de negócio, operações e toda a organização.
Necessidades exploradas e atendidas
![]() Processa novos documentos rapidamente, utilizando Deep Learning, e evita o árduo trabalho de se realizar isso de forma manual.
Processa novos documentos rapidamente, utilizando Deep Learning, e evita o árduo trabalho de se realizar isso de forma manual.
![]() Democratiza o usa da informação em toda a organização, evitando silos de informação oriundos de um mau tratamento dos documentos (ou a falta de um processo de tratamento).
Democratiza o usa da informação em toda a organização, evitando silos de informação oriundos de um mau tratamento dos documentos (ou a falta de um processo de tratamento).
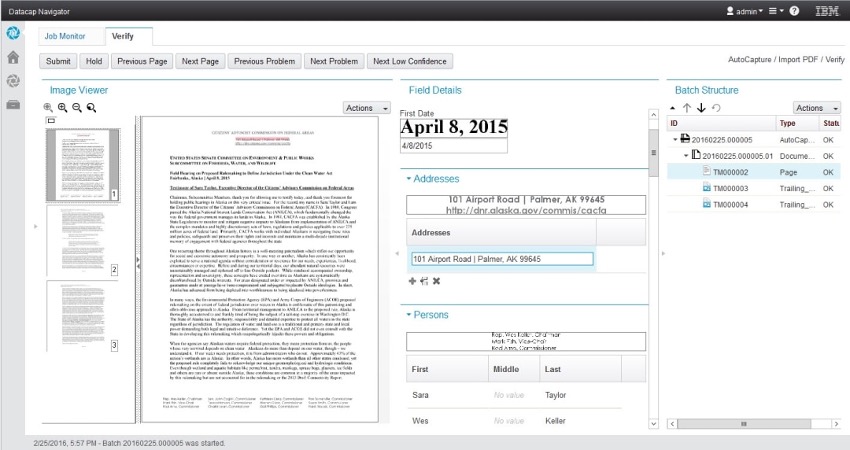
Na imagem 1, um exemplo de extração de contexto e informação em documentos não estruturados.
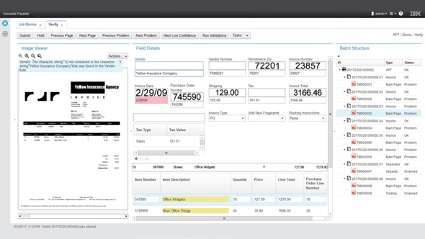
Na imagem 2, um exemplo de extração de campos em documentos estruturados.